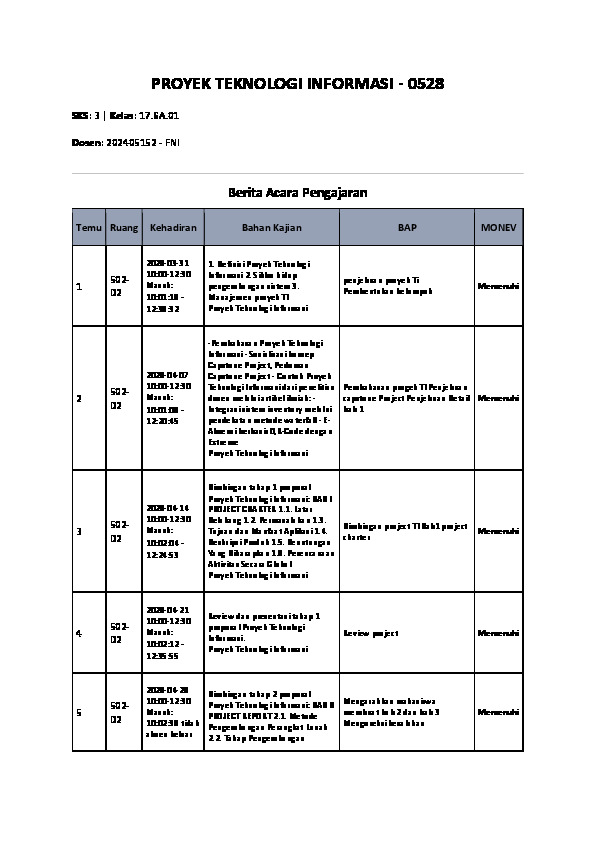
Lion Air is part of PT. Lion Group, which is a airline in Indonesia and a low-cost airline based in Jakarta, Lion Air throughout the year experienced an increase in its fleet and an increase in the number of flights, the greater the need for cabin crew, in addition to the recruitment process which must be selective, it is also necessary to monitor the crew. cabin crew so that cabin crew performance will continue to be well maintained so that several groups are formed called cabin crew monitoring groups, currently cabin crew clustering is carried out randomly so as to produce group members with different characteristics. Clustering should be computerized by utilizing data mining clustering, at the data processing stage by eliminating missing values and determining attributes, it produces 100 data, at the modeling stage the most optimum results obtained using the k-means algorithm are 4 clusters and 6 attributes are indicated by the Davies-value. The Bouldin Index (DBI) is 0.792, while the DBI value for the x-means algorithm is 0.812 and the k-medoids algorithm is 1.700 so that the k-means algorithm is the best algorithm in this study.

Jurnal Perbandingan Algoritma K-Means, X-Means Dan K-Medoids Untuk Klasterisasi Awak Kabin Lion Air
A. N. Khormarudin, “Teknik Data Mining: Algoritma K-Means Clustering,” J. Ilmu Komput., pp. 1–12, 2016.
A. Fauzi, “Data Mining dengan Teknik Clustering Menggunakan Algoritma K-Means pada Data Transaksi Superstore,” 2017.
A. Bastian, “Penerapan algoritma k-means clustering analysis pada penyakit menular manusia (studi kasus kabupaten Majalengka),” J. Sist. Inf., vol. 14, no. 1, pp. 28–34, 2018.
K. Fitriah, “Perbandingan K-Means Clustering, Adaptive K-Means Clustering Dan Fuzzy K-Means Clustering Berdasarkan Internal Validation dan External Validation (Studi Kasus: Pengelompokkan Kabupaten/Kota.” 2017.
D. Arundina, Shaufiah, and T. Suharto, “Implementasi Klasterisasi Menggunakan Algoritma X-Means,” Telkom Univ., 2010.
D. Marlina, N. F. Putri, A. Fernando, and A. Ramadhan, “Implementasi Algoritma K-Medoids dan K-Means untuk Pengelompokkan Wilayah Sebaran Cacat pada Anak,” J. CoreIT, vol. 4, no. 2, p. 64, 2018.
D. F. Pramesti, M. T. Furqon, and C. Dewi, “Implementasi Metode K-Medoids Clustering Untuk Pengelompokan Data Potensi Kebakaran Hutan/Lahan Berdasarkan Persebaran Titik Panas (Hotspot),” J. Pengemb. Teknol. Inf. dan Ilmu Komput. e-ISSN, vol. 2548, p. 964X, 2017.
W. Widiarina and R. S. Wahono, “Algoritma cluster dinamik untuk optimasi cluster pada algoritma k-means dalam pemetaan nasabah potensial,” J. Intell. Syst., vol. 1, no. 1, pp. 33–36, 2015.
M. Mardalius, “Pemanfaatan Rapid Miner Studio 8.2 Untuk Pengelompokan Data Penjualan Aksesoris Menggunakan Algoritma K-Means,” JURTEKSI (Jurnal Teknol. dan Sist. Informasi), vol. 4, no. 2, pp. 123–132, 2018.
F. Marisa, “Educational Data Mining (Konsep dan Penerapan),” J. Teknol. Inf. Teor. Konsep, dan Implementasi, vol. 4, no. 2, pp. 90–97, 2013.